一、.NET使用Redis
和MongoDB一样,在.NET中使用Redis其实也是使用第三方驱动,官网推荐的是使用ServiceStack.Redis

不过看CapQueen的博客时,有提到ServiceStack.Redis 4.0开始收费了,3.9功能不是特别全,一些地方存在不足。而使用了 StactkExchange.Redis ,具体以后详细研究,这里还是使用了ServiceStack.Redis 。
点击下载压缩包,解压 ServiceStack.Redis-master.zip\ServiceStack.Redis-master\build\release\MonoDevelop 下的ServiceStack.Redis.zip 压缩包会有4个dll,我们直接在项目中添加引用即可!

注意:也可以在VS中通过 Nuget直接装到你的项目中, Nuget 命令: Install-Package ServiceStack.Redis.
二、Redis数据类型
Redis目前提供五种数据类型:string(字符串)、list(链表)、Hash(哈希)、set(集合)及zset(sorted set) (有序集合)。下面我们来一一实践一下。
1、String类型
String是最常用的一种数据类型,普通的key/value存储都可以归为此类。一个Key对应一个Value,string类型是二进制安全的。Redis的string可以包含任何数据,比如jpg图片(生成二进制)或者序列化的对象。
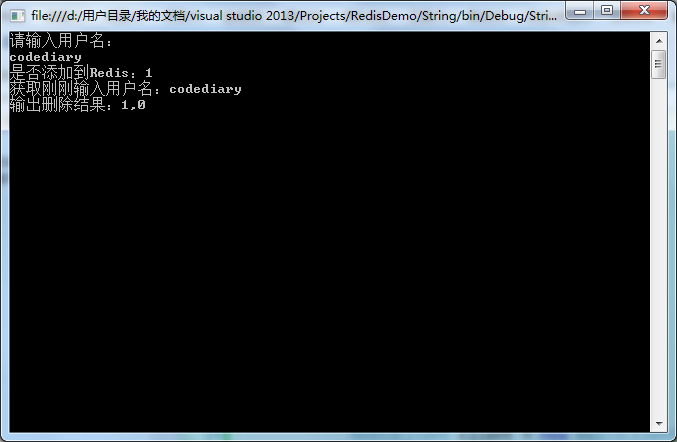
示例:
2、Hash类型
hash是一个string 类型的field和value的映射表。hash特别 适合存储对象。相对于将对象的每个字段存成单个string 类型。一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象。省内存的原因是新建一个hash对象时开始是用zipmap(又称为small hash)来存储的。这个zipmap其实并不是hash table,但是zipmap相比正常的hash实现可以节省不少hash本身需要的一些元数据存储开销。尽管zipmap的添加,删除,查找都是O(n),但是由于一般对象的field数量都不太多。所以使用zipmap也是很快的,也就是说添加删除平均还是O(1)。如果field或者value的大小超出一定限制后,redis会在内部自动将zipmap替换成正常的hash实现. 这个限制可以在配置文件中指定。
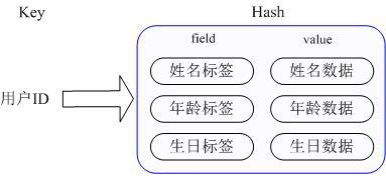
如上图。Redis的Hash实际是内部存储的Value为一个HashMap,这个HashMap的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部HashMap的Key(Redis里称内部HashMap的key为field), 也就是通过key(用户ID) + field(属性标签) 就可以操作对应属性数据了。
示例:

3、List类型
list是一个链表结构,主要功能是push,pop,获取一个范围的所有的值等,操作中key理解为链表名字。 Redis的list类型其实就是一个每个子元素都是string类型的双向链表。我们可以通过push,pop操作从链表的头部或者尾部添加删除元素,这样list既可以作为栈,又可以作为队列。
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
示例:

看以看出队列是FIFO,先入先出,而堆栈是LIFO,后入先出,具体的等后续有时间来填填数据结构的坑。
Redis链表经常会被用于消息队列的服务,以完成多程序之间的消息交换。假设一个应用程序正在执行LPUSH操作向链表中添加新的元素,我们通常将这样的程序称之为"生产者(Producer)",而另外一个应用程序正在执行RPOP操作从链表中取出元素,我们称这样的程序为"消费者(Consumer)"。如果此时,消费者程序在取出消息元素后立刻崩溃,由于该消息已经被取出且没有被正常处理,那么我们就可以认为该消息已经丢失,由此可能会导致业务数据丢失,或业务状态的不一致等现象的发生。然而通过使用RPOPLPUSH命令,消费者程序在从主消息队列中取出消息之后再将其插入到备份队列中,直到消费者程序完成正常的处理逻辑后再将该消息从备份队列中删除。同时我们还可以提供一个守护进程,当发现备份队列中的消息过期时,可以重新将其再放回到主消息队列中,以便其它的消费者程序继续处理。
4、Set类型
在Redis中,我们可以将Set类型看作为没有排序的字符集合,和List类型一样,我们也可以在该类型的数据值上执行添加、删除或判断某一元素是否存在等操作。需要说明的是,这些操作的时间复杂度为O(1),即常量时间内完成次操作。Set可包含的最大元素数量是4294967295。
和List类型不同的是,Set集合中不允许出现重复的元素,这一点和C++标准库中的set容器是完全相同的。换句话说,如果多次添加相同元素,Set中将仅保留该元素的一份拷贝。和List类型相比,Set类型在功能上还存在着一个非常重要的特性,即在服务器端完成多个Sets之间的聚合计算操作,如unions、intersections和differences。由于这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络IO开销。
示例:

可以看出 Set 是无序的。
我们也可以对多个Set进行聚合等操作
例如:
应用场景:
1). 可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问某一博客的唯一IP地址信息。对于此场景,我们仅需在每次访问该博客时将访问者的IP存入Redis中,Set数据类型会自动保证IP地址的唯一性。
2). 充分利用Set类型的服务端聚合操作方便、高效的特性,可以用于维护数据对象之间的关联关系。比如所有购买某一电子设备的客户ID被存储在一个指定的Set中,而购买另外一种电子产品的客户ID被存储在另外一个Set中,如果此时我们想获取有哪些客户同时购买了这两种商品时,Set的intersections命令就可以充分发挥它的方便和效率的优势了。
5、Sorted Set类型
Sorted Set 是Set的一个升级版本,它在set的基础上增加了一个顺序的属性,这一属性在添加修改 .元素的时候可以指定,每次指定后,zset(表示有序集合)会自动重新按新的值调整顺序。可以理解为有列的表,一列存 value,一列存顺序。操作中key理解为zset的名字.
示例:

应用场景:
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构。
1). 可以用于一个大型在线游戏的积分排行榜。每当玩家的分数发生变化时,可以执行ZADD命令更新玩家的分数,此后再通过ZRANGE命令获取积分TOP TEN的用户信息。当然我们也可以利用ZRANK命令通过username来获取玩家的排行信息。最后我们将组合使用ZRANGE和ZRANK命令快速的获取和某个玩家积分相近的其他用户的信息。
2). Sorted-Sets类型还可用于构建索引数据。